概要
当社では、日々終業後に、当日の業務内容を上司へメールで報告します。
週末には、個人が一週間に取り組んだ改善点もあわせて報告します。
前回、過去の改善点の中で「有用な改善点」のみを抽出することを目的として、ネガポジ判定の検証方法まで記載しました。
今回は、実際に仮説について検証した結果及び考察について、記載していきます。
検証
仮説
・ポジティブな改善点は、「有用な改善点」である。
「有用な改善点」と「有用でない改善点」を400件ほど抽出しておきます。(目視で取得)「有用な改善点」で出現する単語のネガポジ平均値と「有用でない改善点」で出現する単語のネガポジ平均値を比較します。
「有用な改善点」 の平均値のほうが「有用でない改善点」の平均値よりも高ければ、仮説の立証としたいと思います。
前回記載した検証方法を実現するために、以下の流れで実施を行います。
①過去の改善点から、「有用な改善点※」と「有用でない改善点」を400件ずつ主観で選定。
※実際に利用して有用な結果が得られた具体的な改善方法が記述されているもの
②「有用な改善点」「有用でない改善点」の内容をそれぞれ形態素解析し、含まれる単語のネガポジ点数の平均値を取得。
<手順>
a) データベースから取得した 「有用な改善点」または 「有用でない改善点」 データをJSONファイルへ出力
f = open('utilitykaizen.json', 'w')
json.dump(utilitykaizen, f, indent=4)
b) aで作成したJSONファイルと単語感情極性対応表(※)を読み込む
# JSONファイルの読み込み
with open('utilitykaizen.json', 'r', encoding = "cp932") as fin:
contents = json.load(fin)
textList = {}
for content in contents.values():
textList[content['id']] = content['kaizen']
# 単語感情極性対応表の読み込み
negapozisort = pandas.read_csv('xxxxx.txt',\
sep = ':',
encoding = 'cp932',
names = ('Word','Read','POS', 'Point'),
)
※http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html
参考文献:高村大也, 乾孝司, 奥村学
“スピンモデルによる単語の感情極性抽出”, 情報処理学会論文誌ジャーナル, Vol.47 No.02 pp. 627–637, 2006.
c) 読み込んだ改善点を分かち書きする(使用ライブラリ:SudachiPy)
from sudachipy import dictionary
from sudachipy import tokenizer
tokenizer_obj = dictionary.Dictionary().create()
# 単名詞・接頭語・接尾語の連続は分解しないモード「C」を使用
mode = tokenizer.Tokenizer.SplitMode.C
# 辞書へのヒット率を上げるため、「normalized_form()」で単語の統一化をしておく※例:シュミレーション→シミュレーション
formatSentence = [m.normalized_form() for m in tokenizer_obj.tokenize(sentence, mode)]
d) cで分けた各々の単語が「単語感情極性対応表」に存在する場合 、単語に対応する点数を配列に追加する。全ての改善点について確認が終了した時点で、配列に追加した単語のネガポジ点数の平均値を取得する。
wordavrp = []
for word in formatSentence:
if word in dic:
wordavrp.append(dic[word])
if(len(avrp) > 0):
avrp = numpy.mean(wordavrp)
③②で取得した平均値を比較。
結果
③で取得したそれぞれの平均値を比較した結果、「有用な改善点」のネガポジ平均点と「有用でない改善点」の平均点には、ほとんど差がないことがわかりました。何故この結果になってしまったかを考察していきます。
| 有用な改善点 | 有用でない改善点 | |
| ネガポジ 平均点 | -0.43115274 | -0.479714569 |
| ネガポジ 最大値 | 0.06581824 | 0.1523875 |
| ネガポジ 最小値 | -0.762031222 | -0.8812604 |
考察
1. 頻出単語に違いについて
今回選定した、「有用な改善点」と「有用でない改善点」で頻出している単語がそもそも異なっているかどうかを確認しました。
以下の図1、図2では、それぞれの頻出単語を表した図となっており、「為る」という単語がどちらも多いことがわかります。また、「出来る」「改善」「作業」といった単語も両方で多くでており、頻出単語がそこまで変わっていないように見えます。そのため、どちらの平均点もそこまで変わらなかった可能性があります。
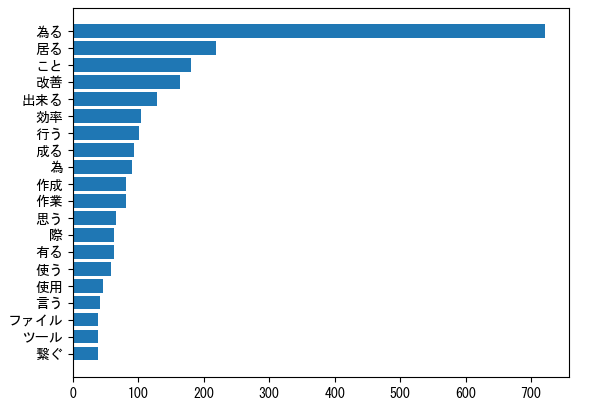
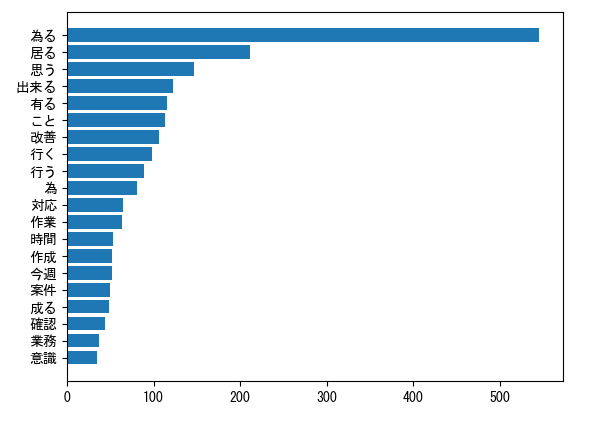
2.単語帳の見直し
今回使用しました、単語感情極性対応表についてネガポジの点数を確認しました。
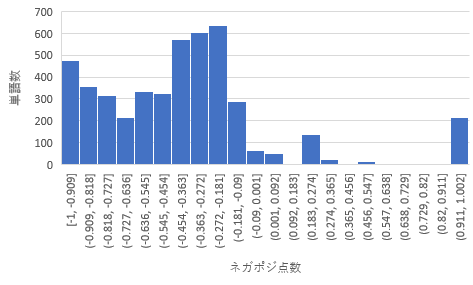
図3は、横軸がネガポジの点数、縦軸が単語数となっています。
全体的にマイナスの単語が多く、-0.5から-0.09の間の単語が多いです。
今回の「有用な改善点」と「有用でない改善点」でヒットした単語でネガポジ点数のヒストグラムをそれぞれ図4、図5で表してみたところ、「有用な改善点」と「有用でない改善点」のヒストグラムは、全体のヒストグラムの形に似たような形になっていることが分かります。
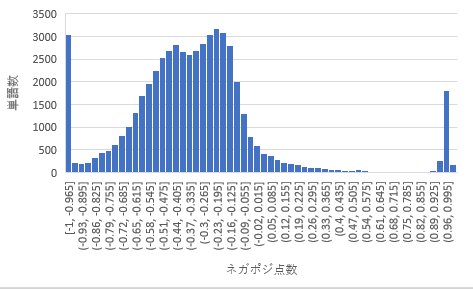
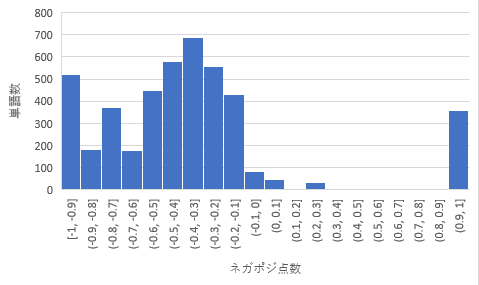
まとめ
上記考察より、今回使用した辞書で検証した結果、「有用な改善点」は、「有用でない改善点」に比べてポジティブな文章であるとは言えないことが分かりました。
そのため、現状本目的である有用な改善点のみ抽出するには、ネガポジ判定のみでは難しいことが判明しました。
今後
今回の検証では、『ポジティブな改善点は、「有用な改善点」である』という仮説の立証は出来ませんでした。
有用かどうかを判定するために、Word2Vec等のライブラリを使用し、判定用の辞書を作成することで、
有用な改善点を抽出を目指していければと思います。