概要
前回のおさらい。
“ヤクルトレディGO!!(*)”の一連の流れを構築するための、環境構築・実装をした。
yolov5に元々ついているデフォルトモデルを使用して、分析してみた。
※ 詳しくは【物体検知】来客を分析し、Teams通知してみた(環境構築/実装編) を
ご覧ください。
今回は、収集したヤクルトさん画像、社員画像を使って、「yakult」モデルを構築してみます。
(*) : ある方から「ヤクルトさんが来た!通知システム」の名前を頂戴しました。
モデル構築編
おおまかには、以下の手順で行います。
- 収集した画像を「ヤクルトさん OR 社員」にラベリング
- 分析に適したフォルダ構成に仕分け
- トレーニング(★学習モデル構築)
- トレーニング結果を使って、動作確認
順を追って説明します。
収集した画像を「ヤクルトさん OR 社員」にラベリング
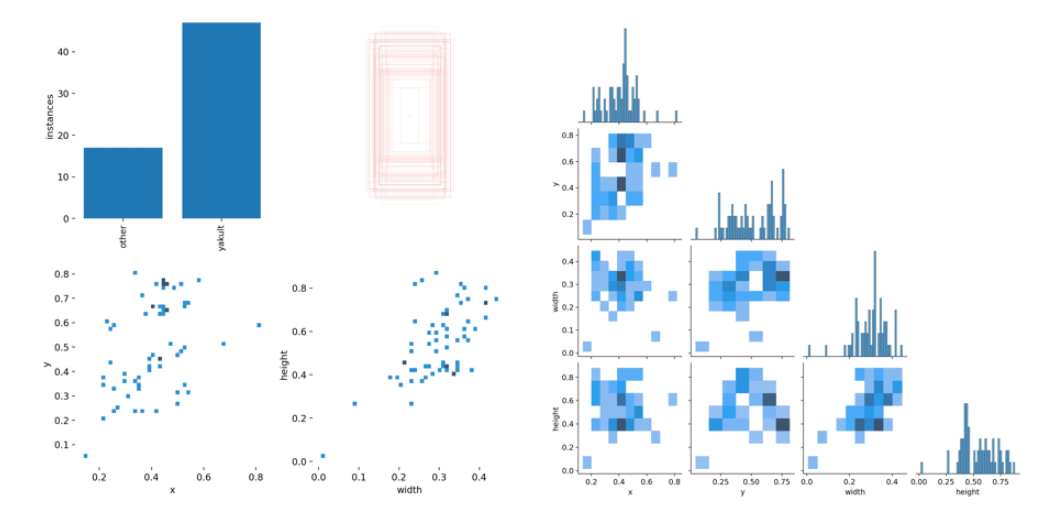
以下のような画像がラズパイで取れてます。

これを「LabelImg」などのラベリングツールを使って
地道にラベリング(これも自動化できたら素敵ですよね~)
※ ラベリング作業の詳細なやり方はこちら

ラベリング結果は以下のような形式になっています。
# [oject-class] [x_center] [y_center] [width] [height]
# object-class : 0(other{社員}), 1(yakult{ヤクルト})としてます
0 0.348438 0.327083 0.309375 0.637500 // この例では、otherのバウンディングボックス情報
分析に適したフォルダ構成に仕分け
yolov5のGithubページを参考に、yolov5トレーニングに適したフォルダ構成に整えます。
以下のような構成です。
YOLOv5では、学習のために、画像とアノテーションファイル(上記のバウンディングボックス情報)
のペアが必要になります。
data
└ train
| └ images
| └ *.jpg
| └ labels
| └ *.txt
└ data.yaml
次に、data.yamlを作成します。
ここには、train.py(YOLOv5のトレーニングする際のpythonプログラム)に必要な情報を定義します。
今回は以下の通り
train: data/train/images # 学習の画像のパス
val: data/train/images # 検証用画像のパス(★今回は検証用画像も学習用パスと同じに指定、それでもできた?)
nc: 2 # クラスの数
names: [ 'other', 'yakult' ] # クラス名
トレーニング(★学習モデル構築)
ここまで、準備できれば、あとはトレーニング用pythonプログラムをたたいて、学習開始です。
python train.py --img 640 --batch 20 --epochs 50 --data '/data/data.yaml' --name yakulto
上記の引数は以下の通りです。
・ img:画像サイズを指定(default=640のようで、指定する必要はなかった?)
・ data:データセットを指定。
・ epochs:エポック数(学習回数)を指定。
ほかにも大量の引数を指定できるよう、ここでは割愛します (詳しく知りたい方は、”YOLOv5 github”等で検索)
トレーニング結果
トレーニング結果は、以下のように、画像として出力されます(写真は一部加工してあります)

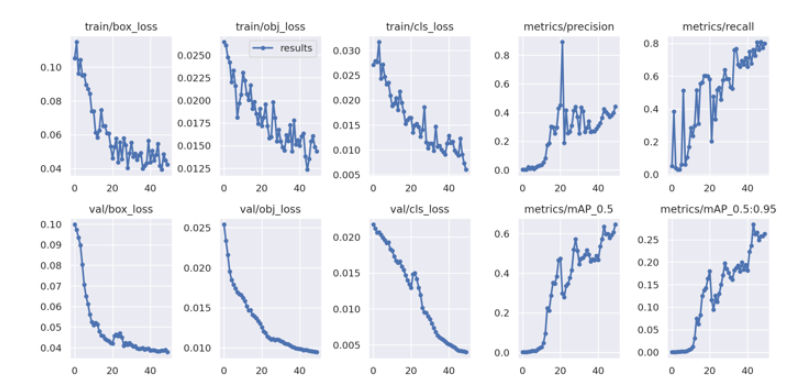
結果の見方
■ metrics/precision
適合率
■ metrics/recall
再現率
■ metrics/mAP_0.5
平均適合率
■ metrics/mAP_0.5:0.95
さまざまなIoU閾値(ステップ0.05{0.50, 0.55, 0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90 ,0.95}
どういうこと、、、
ここは専門的な知識が必要ですね。
「APを全てのクラスについてさらに平均したもの」ということみたいですが、
多分に数学知識が必要なようです。
数学の先生がわが社には二人もおられるので、この辺はお任せします
動作確認
では、最後に構築した「yakult」モデルを使用して、分析してみます!
結果:
50%以上の確率でヤクルトさんのようです。(写真は一部加工してあります)

誤検知も目立ちます(写真は新入社員Sくん)(写真は一部加工してあります)

更には、ヤクルトさん全体でなく、ヤクルトさんのもつ特徴的な鞄も「yakult」と
ラベリングしてしまった結果、こんなことにも。(写真は一部加工してあります)

まとめ
無事、ヤクルトさんモデルが構築できました(精度はさておき)
ラベリング作業が大変です。また、今回学習に一番時間のかからないモデルを使用しての
トレーニングだったので、2時間程度?でできました(その分精度も悪い)
社内に性能のよい遊び用GPUマシンがあればなあ~と思ってみたりしました。
次回、最終回です。
最後は、ラベリング数を「yakult, other」それぞれ200枚、学習回数も回数増やしたり、学習モデルも精度の高いもの使ってみたりして、実際のTeams通知システムを完成されます。