
はじめに
Athenaというjsonやcsvなどのファイルに直接クエリをかけられるサービスがあることを知ったので、試しにどんなものか触ってみて、使用感や操作方法など共有出来たらと思います。
S3設定
AthenaでS3に保存したファイルにクエリをかけるため、まずはS3バケットを作成します。
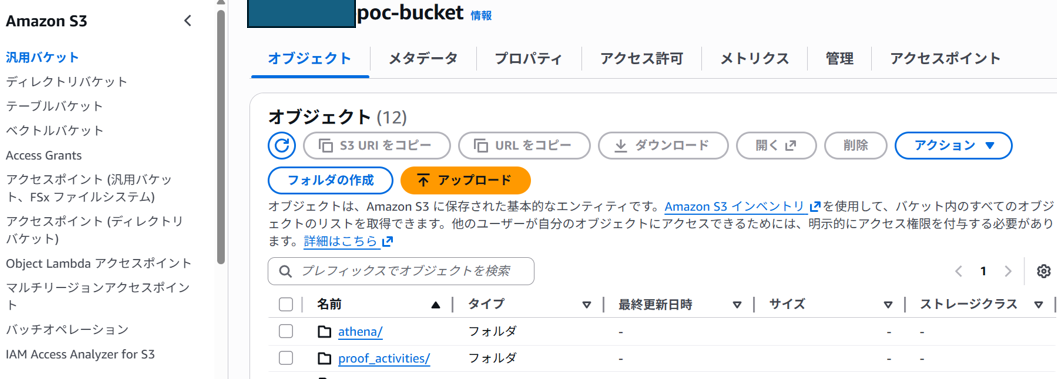
Athenaでテーブルを作成する際に、S3のjsonファイルを配置している場所と、テーブル名をリンクさせる必要があるため、”proof_activities” というフォルダを作成します
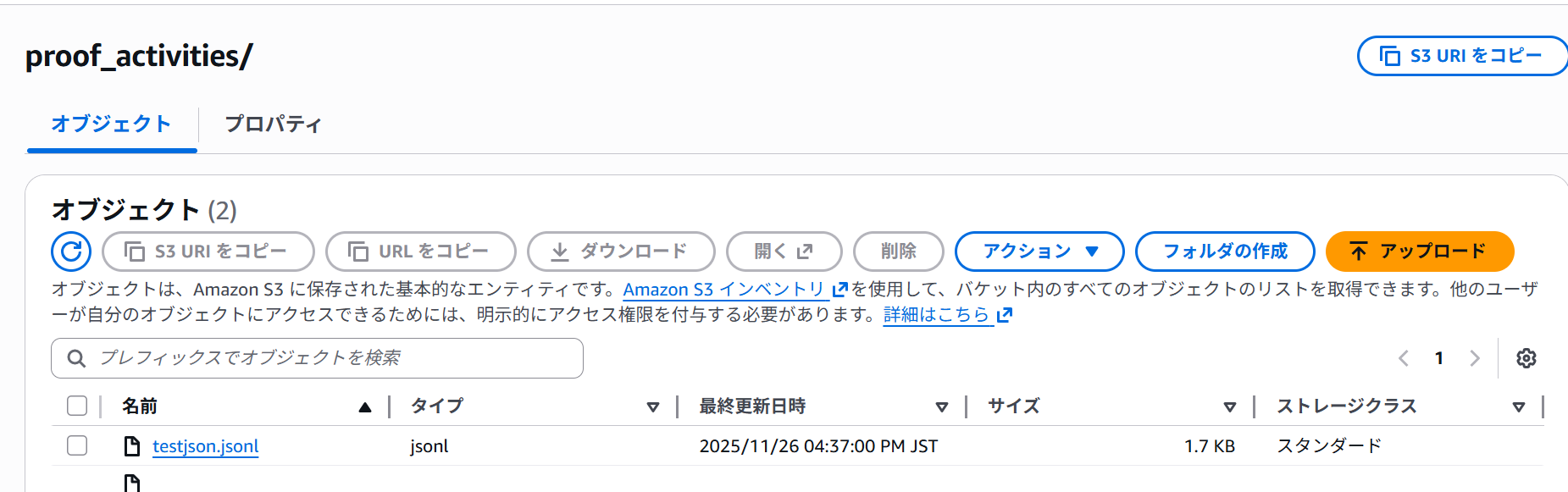
作成したフォルダの中に、今回クエリをかけるjsonファイルをアップロードしておきます。
Athenaでjsonファイルにクエリをかける場合、1行1オブジェクトの形としておく必要があります。
testJson.jsonl

実際の運用ではjsonファイルを作成、アップロードまではlamdaで実装するようになると思います。
Athena
先ほど作成したjsonファイルのカラムをテーブルに定義していきます。
Athenaのカラムの設定方法はここでは詳しく説明はしません。
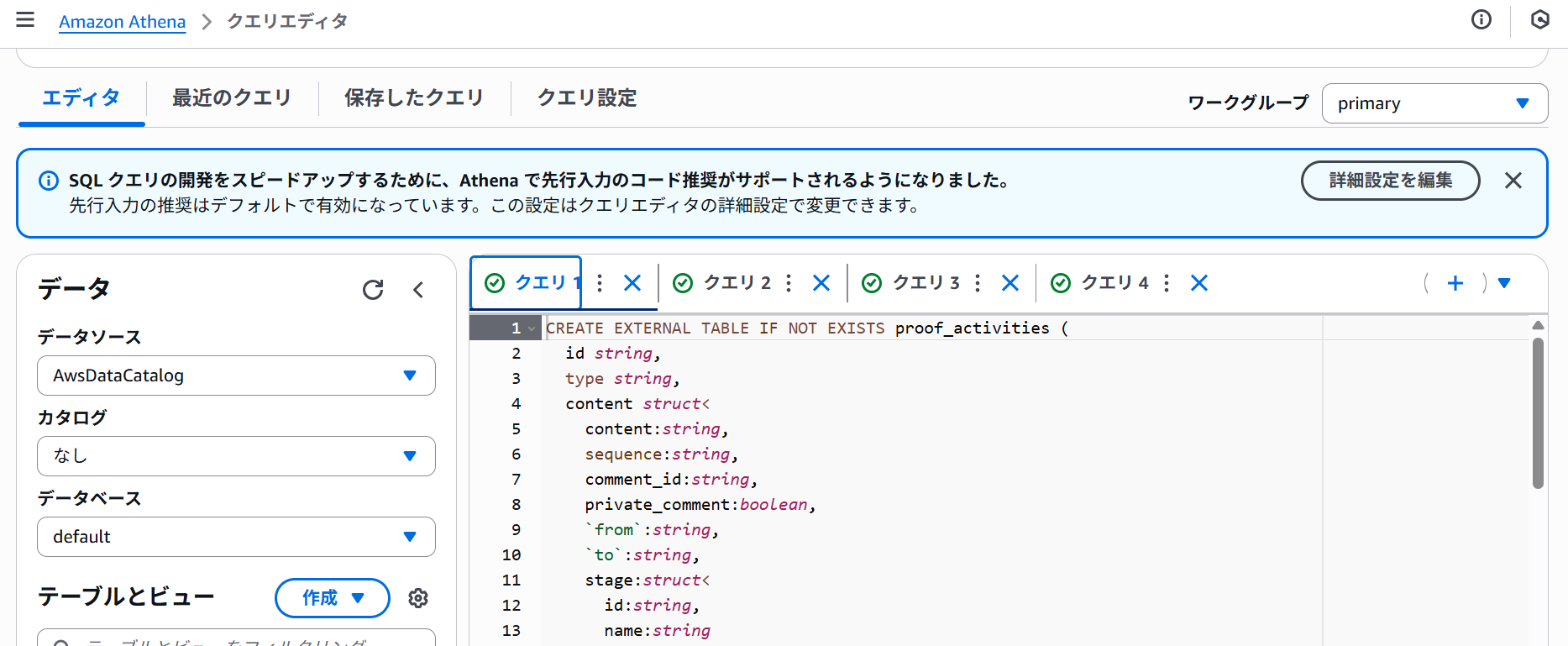
Athenaのクエリで下記を実行しテーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS proof_activities (
id string,
type string,
content struct<
content:string,
sequence:string,
comment_id:string,
private_comment:boolean,
`from`:string,
`to`:string,
stage:struct<
id:string,
name:string
>,
reviewer:struct<
id:string,
contact:struct<email:string>
>,
new_attachments:array<struct<file_id:string, name:string>>,
removed_attachments:array<struct<file_id:string, name:string>>,
new_labels:array<struct<label_id:string, label:string>>,
removed_labels:array<struct<label_id:string, label:string>>,
date:string,
folder:struct<id:string, name:string>,
changes:array<struct<type:string, `from`:string, `to`:string>>
>,
action_maker struct<
contact_id:string
>,
created_date string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://{バケット名}/proof_activities/';
テーブルができたので、SELECT文でデータを取得します。
SELECT id, content."from" AS from_status, content."to" AS to_status, content.stage.name AS stage_name, content.reviewer.contact.email AS reviewer_email, created_date FROM proof_activities LIMIT 10;
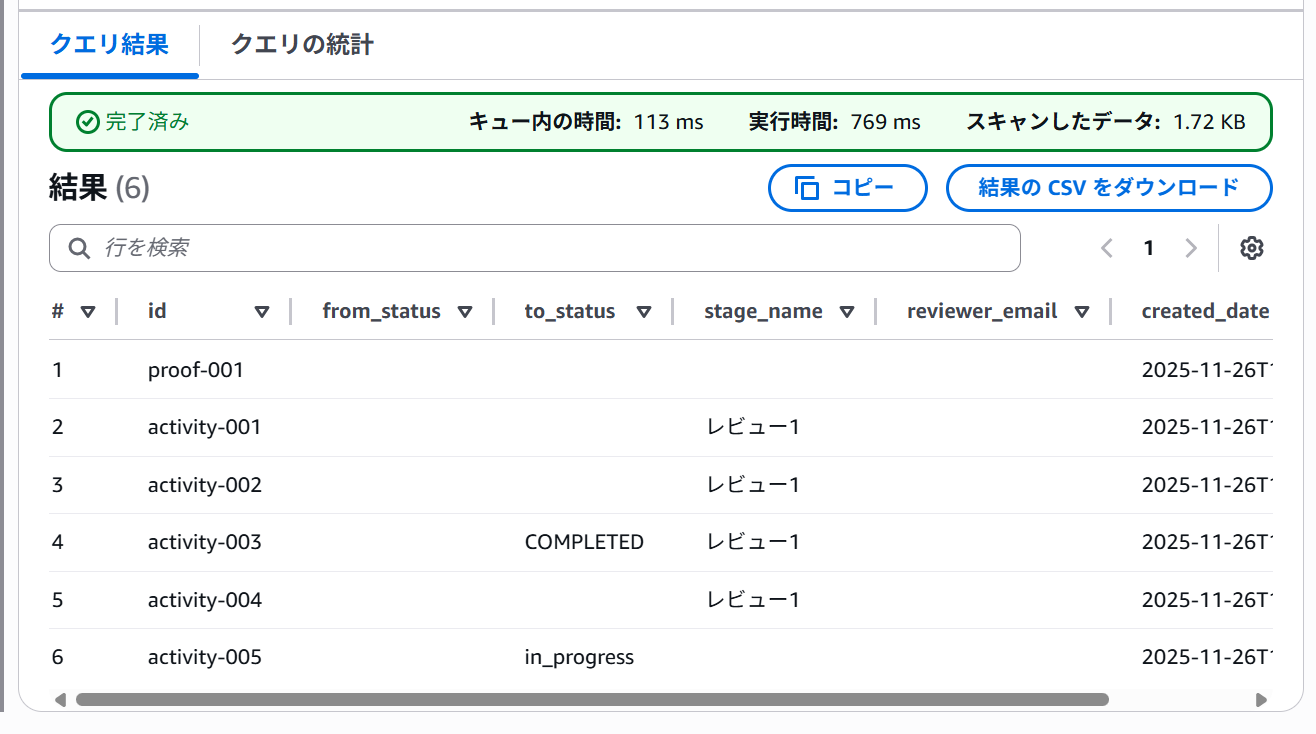
jsonのカラムが抽出できていることを確認できました。
まとめ
Athenaを使って驚きました。DBに保存してからクエリする常識が崩れ、S3に置いたままSQLで分析できるのは革命的。インフラ管理不要で、次世代のデータ活用ってこういうことなんだと実感しました。