前回(DBを使ったIPアドレス管理~任意のレンジで抽出する~)、煩わしいIPアドレスの管理をDBを利用してもっとスマートに行なえないかを考えてみましたが、実装上の弱点が残ってしまいました。
今回はその弱点を解決すべく検討した結果です。
前回のおさらい
前回出た弱点をおさらいします。
- 事前に管理範囲すべてのレコードをInsertしておく必要がある
- インデックス付与が難しい
2のインデックスについては(元の設計が致命的でない限り)、最近のRDBMSを使っていれば運用しながらチューニングすることが比較的容易ですので、今回は取り上げません。
今回は1の膨大な管理用レコードの存在をどうにかしたいと思います。
アドレス管理の運用と実装
IPアドレス管理がどのように運用されるのか、という点についての検討が浅いのですが、思いつくところで以下のようなものがあります。
(/32を含む)任意のアドレスのレンジについて、
- すでに割当て済みかどうかを確認する
- 新たに割り当て可能かどうかを確認する
- 割当て済みとして登録する
- 特定用途向け範囲として予約登録する
これらの作業は割当て済みのレコードに被っているかどうかを調べれば結果を得ることができますので、管理用レコードは必要ないことがわかります。
(/32を含まない)任意のアドレスのレンジについて、
- 任意のプレフィックスのレンジとして割当て可能なアドレスを確認する
思いつく運用の中で管理用のレコードが必要な場合というのは、以下の一点だけです。
この一点のために大量の管理用レコードをあらかじめ投入しておくのは少しもったいないというかばからしい感じがします。
そこで、集合演算で言うところの「積集合」を利用して、少量の管理用レコードで代用しましょう。
要は0~255の数値レコードを持つテーブルを4回JOINすれば255×255×255×255と同じ結果が得られる、ということになります。
テーブルとテーブル操作クラス
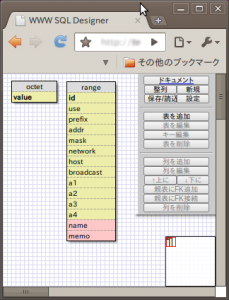
今回はこのようなテーブルを準備しました。

octetテーブルは最初に0~255の数値レコードを入れた後は編集しません。
rangeテーブルはロングIP形式で1つのレンジに関する情報と、それ以外にも「予約/割当済み」判別用の”use”、ドットアドレスの”a1~a4″、人間向け記録領域としての”name”、”memo”などがあります。
rangeテーブルへのInsertが手間なので、実験用クラスIPv4Rangeを作成しました。
記事の最後にダウンロードリンクを設けていますが、利用の際は以下の点に注意が必要です。
- 実験用の機能でまとめているため、IPv4アドレス範囲に関する機能群として利用できるものではありません。
- ↑の理由から、クラス定数にDB接続情報を定義していますので、本番用途では利用しないほうが良いと思われます。
- Ruby標準クラスにIPAddrクラスが存在していますが、アドレス範囲に特化した今回の用途では使い勝手が良くないため、敢えて使っていません。
IPv4Rangeを簡単に利用するためにいくつかのコマンドを準備し、それに沿って説明を進めます。
初期化
先ずはテーブルの作成と初期データの投入を行ないます。
setup_ipv4_range.rbの中でIPv4Range::setupとIPv4Range#insert_rangeを呼び出しています。
$ ruby setup_ipv4_range.rb
$
特に出力はしないので、DBに期待したレコードが挿入されていればOKです。
初期データは前回(DBを使ったIPアドレス管理~任意のレンジで抽出する~)の「管理の例」と同じ内容です。
使用済レンジとの重複
次に、任意のレンジが登録済みのレンジに被っていないかを確認してみます。
コマンドoverlap_ipv4_range(実体はIPv4Range#overlap?およびIPv4Range#overlap)を使います。
$ ./overlap_ipv4_range 192 168 10 240 28
“192.168.10.253-192.168.10.253(/32)”
“192.168.10.254-192.168.10.254(/32)”$ ./overlap_ipv4_range 192 168 10 64 27
“192.168.10.64-192.168.10.79(/28)”
“192.168.10.80-192.168.10.95(/28)”
2つのパターンで試してみましたが、問題なさそうです。
利用可能なレンジの一覧
ではいよいよ前回の最後に確認した192.168.10.0/24のレンジ中、/29で払い出せるレンジの一覧を取得してみます。
コマンドusable_ipv4_range(実体はIPv4Range#get_usable_blockおよびPv4Range::long_to_dot)を使います。
$ ./usable_ipv4_range 192 168 10 0 24 29
“192.168.10.24/29”
“192.168.10.96/29”
“192.168.10.104/29”
“192.168.10.112/29”
“192.168.10.120/29”
“192.168.10.136/29”
“192.168.10.144/29”
“192.168.10.152/29”
“192.168.10.160/29”
“192.168.10.168/29”
“192.168.10.176/29”
“192.168.10.184/29”
“192.168.10.192/29”
“192.168.10.200/29”
“192.168.10.208/29”
“192.168.10.216/29”
“192.168.10.224/29”
“192.168.10.232/29”
“192.168.10.240/29”
前回と同じ結果が得られました。
パフォーマンス
今回はあくまで試作であるため、テーブルもSQLもチューニングは行なっていません。
しかし、(IPv4Range#get_usable_block内の)抽出用SQLについては、最低限ですが事前に不要な結合を省くようにしています。
では現状のパフォーマンスは実用に耐え得るものなのでしょうか?
試しに、192.168.0.0/16のレンジ中、/24で払い出せるレンジの一覧を取得、つまり192.168.10.0/24以外の255行の抽出を行なってみます。
$ ./usable_ipv4_range 192 168 10 0 16 24
“192.168.0.0/24”
“192.168.1.0/24”
“192.168.2.0/24”
“192.168.3.0/24”
“192.168.4.0/24”
“192.168.5.0/24”
“192.168.6.0/24”
“192.168.7.0/24”
“192.168.8.0/24”
“192.168.9.0/24”
“192.168.11.0/24”
~中略~
“192.168.255.0/24”
/24だけでなく、/23~/30まで試してみましたが、結果が表示されるまで約3秒といったところでしょうか。
これを速いととらえるか遅いととらえるかは意見が分かれるかも知れませんが、
- 実験段階(未チューニング)であること
- 管理用レコード数の削減に成功していること
この2点を考慮すればまずまずのパフォーマンスが出ていると思います。
おわりに
今回は説明が長くなってしまい、肝心の実装部分に関する説明ができませんでした。
不本意ではありますが、詳しい内容はソースを読んでね、という終わり方はになってしまいました。
申し訳ありません。
今回作成したクラスとコマンド
今回作成したクラスとコマンドはここからダウンロードしてください。
【ダウンロード】20100712_ipv4range.zip
以上です。